KAIST, 전기및전자공학부 유민수 교수 연구팀, 국제 고성능 컴퓨터 구조 학회에서 최우수논문상(Best Paper Award) 수상
- 실제 상용화된 PIM 제품을 기반으로 한 오픈소스 시뮬레이터 제작 성공해 제출된
논문 410편 중에서 1등 수상
 |
| KAIST 전기및전자공학부 유민수 교수, 현봉준 박사과정, 이동재 박사과정, 김태훈 박사과정- |
 |
| 상장 그림 |
KAIST 연구진이 컴퓨터 구조 분야 국제 최우수 학술대회에서 최우수논문상을 국내 최초로 수상했다. 이는 제출된 논문 410편 중에서 상위 1편에만 주어진 영예다.
KAIST 전기및전자공학부 유민수 교수 연구팀이 국제 최우수 컴퓨터 아키텍처 학술대회 중의 하나인 ‘IEEE 국제 고성능 컴퓨터 구조 학회(IEEE International Symposium on High-Performance Computer Architecture, HPCA)’에서 최우수논문상(Best Paper Award)을 수상했다고 21일 밝혔다.
KAIST 전기및전자공학부 현봉준 박사과정(제1 저자), 김태훈 박사과정, 이동재 박사과정으로 구성된 유민수 교수 연구팀은 프랑스 기업 UPMEM 社의 상용화된 프로세싱-인-메모리(Processing-In-Memory, PIM) 기술을 기반으로 한 ‘유피뮬레이터(uPIMulator)’라는 시뮬레이션 프레임워크를 제안하여 최우수논문상을 수상했다.
최근 주목받고 있는 챗GPT와 같은 대형 언어 모델(Large Language Model) 및 추천시스템은 많은 양의 메모리 대역폭(메모리에서 한 번에 빼낼 수 있는 데이터의 양)을 요구하는 특성을 지닌다. 기존의 CPU 및 GPU 기반 시스템은 물리적 한계로 인해 이러한 증가하는 메모리 대역폭의 수요를 충족시키는 데 있어 제약이 따른다.
제한된 메모리 대역폭 문제를 해결하기 위해, 메모리 내부에 연산 장치를 통합하는 PIM 기술이 주목받기 시작했다. PIM 기술은 학계뿐만 아니라 산업계에서 각광을 받으며, 메모리 반도체와 인공지능 프로세서가 하나로 결합한 삼성전자의 HBM-PIM, SK 하이닉스의 생성형 AI 특화 가속기인 AiMX와 같은 PIM 프로토타입 제품의 공개뿐만 아니라, UPMEM 社의 UPMEM-PIM 제품을 통한 상용화 사례로 그 가능성을 입증하고 있다.
그러나 현재 PIM 기술은 CPU나 GPU와 같은 하드웨어 구조의 발전 수준에 비해 상대적으로 초기 단계에 머물러 있으며, 폭넓은 하드웨어 구조에 관한 연구가 요구된다. 다양한 하드웨어 설계 영역 탐색을 위해 하드웨어를 모사하는 시뮬레이터가 학계 및 산업계에서 자주 활용되지만, PIM을 위한 시뮬레이터 연구는 상대적으로 미비한 현실이다.
유민수 교수 연구팀은 상용 PIM 기술, UPMEM-PIM 제품을 기반으로 한 설계 및 검증을 거친 시뮬레이터 개발을 통해 PIM의 성능, 견고성, 보안성을 개선할 수 있는 다양한 하드웨어 구조를 탐색했다. 이 연구는 실제 PIM 제품에 근거한 시뮬레이터를 통해 PIM 하드웨어 구조에 대한 상세한 분석 및 다양한 설계 방향성을 탐색하는 데 의의가 있으며, 개발된 시뮬레이터는 현재 오픈소스로 공개돼(https://github.com/VIA-Research/uPIMulator) 연구 및 개발 커뮤니티에 기여하고 있다.
상을 수상한 KAIST 전기및전자공학부 유민수 교수는 “이번 성과를 바탕으로 앞으로의 연구 발전에 더욱 기여할 수 있도록 노력하겠다. 함께한 모든 학생들에게도 감사의 마음을 전한다” 라고 수상 소감을 전했다.
한편 이번 연구는 정부(과학기술정보통신부)의 재원으로 한국연구재단, 정보통신기획평가원, 그리고 삼성전자의 지원을 받아 수행됐다.
□ 연구개요
연구 배경
프로세싱-인-메모리(Processing-In-Memory, PIM)는 기존 컴퓨터 구조에서 쓰이는 폰 노이만 구조의 한계를 극복하기 위해 개발된 기술로, 데이터 처리를 위한 연산 장치를 메모리 내부에 통합함으로써 프로세서와 메모리 간 데이터 이동에 필요한 시간 및 에너지를 절약하여 컴퓨팅 효율을 향상시킬 수 있다. 이는 특히 인공 지능, 빅 데이터 분석, 고성능 컴퓨팅 분야와 같이 대용량 데이터의 처리를 요구하는 분야에서 활용도가 높을 것으로 기대되며 이에 기반한 여러 연구들이 진행되어왔다. 최근 삼성전자, SK 하이닉스 그리고 UPMEM社에서 PIM 기술을 활용한 제품을 출시하여 PIM에 대한 관심이 고조되고 있으며, 특히 UPMEM社가 출시한 UPMEM-PIM은 널리 사용되는 메모리 모듈인 DIMM 폼팩터에 범용 프로세서를 통합한 형태로, 프로그래밍이 가능하여 다양한 분야에서 활용될 수 있을 것으로 기대된다. 그러나, 상용화된 PIM 프로세서가 연산의 과정에서 갖는 특성 및 병목점을 파악할 수 있는 도구의 부재와 PIM 프로세서의 구조 변경 시 성능 변화를 파악하기 어렵다는 제한점이 존재한다. 따라서, 본 연구는 이런 제한점을 해결하기 위해 UPMEM-PIM을 모사하는 시뮬레이션 프레임워크를 개발하였다.
2. 연구 내용
 |
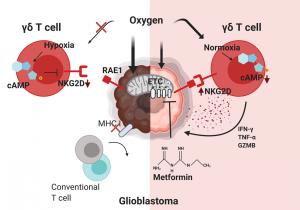
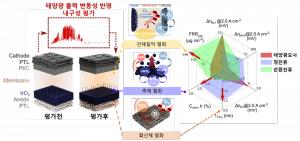
| 유민수 교수 연구팀이 개발한 시뮬레이터 구조 모식도 |
이 연구는 UPMEM-PIM을 모사한 시뮬레이션 프레임워크(그림 1)을 제안하고, 이를 활용해 UPMEM-PIM의 성능을 측정하기 위해 개발된 벤치마크를 실행하여 다양한 특성 분석을 진행하였다.
 |
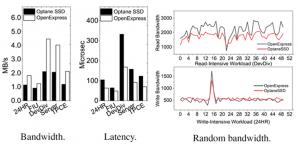
| 그림 2. 시뮬레이션 프레임워크를 활용한 자원 활용도 분석 |
특성 분석 결과, 전통적인 폰 노이만 구조에서 메모리 대역폭에 의해 성능이 제한되는 메모리-바운드(memory-bound)의 특성을 갖는 다수의 벤치마크가 연산 장치의 처리량에 의해 성능이 제한되는 컴퓨트-바운드(compute-bound)의 특성을 갖는 것을 확인함으로써 PIM을 활용해 이러한 워크로드를 실행하는 것이 이점이 있음을 검증하였다(그림 2). 이뿐만 아니라, 각 벤치마크를 실행하는 과정에서 연산 및 메모리 자원의 활용도, 실행된 명령어 종류 등을 자세히 분석할 수 있는 기능을 제공하여 현재 PIM 구조의 병목점을 찾고 이를 해결할 수 있는 하드웨어 구조에 대한 연구를 진행하는데 큰 도움을 줄 것으로 판단된다.
 |
| 그림 3. ILP 향상을 위한 마이크로아키텍처 변화에 따른 성능 개선 정도 |
이러한 과정의 일환으로, 본 연구는 기존의 UPMEM-PIM에 명령어-수준 병렬화(instruction-level parallelism, ILP)를 강화하는 구조를 추가하여 성능 변화를 측정하였으며(그림 3), 그 밖에도 SRAM 메모리 구조 비교(스크래치 패드 메모리 대 캐시 메모리), SIMT 구조의 성능향상 정도를 파악하는 등 다양한 활용처를 제시하였다.
3. 기대 효과
현재 PIM 기술은 CPU/GPU와 같은 프로세서의 발전 수준에 비해 상대적으로 초기 단계에 머물러 있어, 폭넓은 하드웨어 구조에 대한 연구가 요구된다. 본 연구에서 제안한 시뮬레이션 프레임워크는 현재 PIM 구조의 특성을 보다 면밀히 분석할 수 있는 기능을 제공하여 여러 워크로드의 병목점을 파악하는데 활용 가능하며, 병목점을 해결하기 위한 하드웨어 구조 탐색 과정에 도움을 주어 미래 PIM 구조의 방향성을 제시하는데 이바지를 할 것으로 기대된다.
KAIST 홍보실 제공
노벨사이언스 science@nobelscience.co.kr